 -
Robert Tolksdorf
- Fabio Vitali
-
Robert Tolksdorf
- Fabio Vitali
Title:
Distributed Applications on the WWW:
Coordinating Java Agents with PageSpace
Authors:
Paolo Ciancarini
Dept. of Computer Science,
Univ. of Bologna,
Pza. di Porta S. Donato, 5,
I-40127 Bologna, Italy.
mailto:cianca@cs.unibo.it
Robert Tolksdorf
Technische Universität Berlin,
Fachbereich 13, Informatik,
FLP/KIT, FR 6-10,
Franklinstr. 28/29,
D-10587 Berlin, Germany.
mailto:tolk@cs.tu-berlin.de
Tel: +49-30-314-25184
FAX: +49-30-314-73622
Fabio Vitali
Dept. of Computer Science,
Univ. of Bologna,
Pza. di Porta S. Donato, 5,
I-40127 Bologna, Italy.
mailto:vitali@cs.unibo.it
Davide Rossi
Dept. of Computer Science,
Univ. of Bologna,
Pza. di Porta S. Donato, 5,
I-40127 Bologna, Italy.
mailto:rossi@cs.unibo.it
Andreas Knoche
Technische Universität Berlin,
Fachbereich 13, Informatik,
FLP/KIT, FR 6-10,
Franklinstr. 28/29,
D-10587 Berlin, Germany.
mailto:knoche@cs.tu-berlin.de
Keywords:
Java, Linda, Coordination, Internet, Web
Applications,
Open Distributed Systems
Paolo Ciancarini
-
Robert Tolksdorf
- Fabio Vitali ![]() - Davide Rossi
- Davide Rossi ![]() - Andreas Knoche
- Andreas Knoche ![]()
The current Web does not support distributed applications well. Existing approaches are oriented to centralized applications at servers, or local programs within clients. To overcome this deficit, a platform for distributed, coordinated Java agents within the Web is designed with PageSpace.
We take a specific approach to coordinate agents in PageSpace applications, namely variants of coordination language Linda that support rules and services to guide their cooperation. This technology is integrated with the standard Web technology and the programming language Java.
Several kinds of agents life in the PageSpace: User interface agents, personal homeagents, the agents that implement applications, and the kernel agents of the platform. Within the architecture it is possible to support fault-tolerance and mobile agents as well.
Keywords: Java, Linda, Coordination, Internet, Web Applications, Open Distributed Systems
The Web has evolved into the dominating platform for information systems on the Internet. There is increasing demand to use it as a platform for distributed applications in which processing of information occurs. For example, the application domains workflow management and electronic commerce are classes of applications that require distributed access and processing due to the distributed nature of the work these applications support. Still there is no widely accepted platform for implementing distributed applications on top of the Web.
PageSpace is such a platform that has the potential to provide sufficient functionalities to do so. It is based on the core Web technology for access and presentation, on Java as the execution mechanism, and on coordination technology to manage the interaction of agents in a distributed application. This paper describes the rationale for our platform, its design, and the implementation strategy currently applied.
Currently, the field of electronic commerce is of particular interest for the application of platforms like PageSpace. In fact, electronic commerce should serve as a benchmark for the validation of our approach wrt. applications requirements. Appendix A summarizes the requirements.
This paper is organized as follows. In the following section, we review approaches to implement applications that require active processing on the Web. We then describe the technology, on which our specific approach to coordination in distributed applications is based. The next section describes the PageSpace platform and its various kinds of agents. Then, the current approach taken in engineering and implementing PageSpace is outlined. We finally point out how the design can support fault-tolerance and mobility of agents. A summary and the bibliography conclude the paper.
Since 1993 the Web as the dominating Internet service has evolved into the most popular and widespread platform for world wide accessible information systems. The software for accessing and offering information on the Web is available in the public domain for all hardware and operating system platforms in use.
At its core, the Web is a static hypertext graph in which multimedia pages of information marked up in HTML are offered by servers, retrieved by clients with the HTTP protocol and displayed in a graphical interface that is very easy to use. Because of its high availability, it becomes more and more desirable to use the Web as a platform for dynamic, distributed applications. The support of the core Web platform for applications is very rudimentary - only the CGI mechanism allows for processing of information that is entered by the user in forms, or retrieved from auxiliary systems, such as database servers.
A number of mechanisms has been proposed and implemented to make the Web a platform for distributed applications. The following classification is structured according to the loci of activity that are possible with such mechanisms.
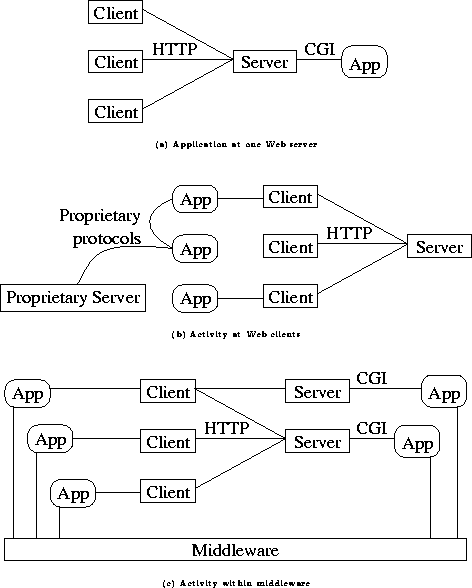
Figure 1: Activity in Web applications
However, with respect to the aspect of distribution of an application, this approach turns out to have nothing in common with distributed paradigms like client-server interaction, or others. In fact, interfacing an application via CGI to the Web does not mean to offer a distributed application. There is no processing at the client besides displaying results. Moreover, there is only one central location of activity. Thus, such an application is basically a mainframe/terminal system at a large spatial scale. The Web server is like the mainframe - the only location of processing. The Web browsers are nothing but easy to use and graphical terminals, that use HTML as the display language.
Figure 1(b) shows this structure of activity focused on clients, which contains no generally accepted framework for distributed applications on the Web.
The PageSpace platform ([CKTV96]) is based on the notion of agents that use coordination technology for their interactions. We use the term agent reflecting that processing is performed in such an entity. Applications are composed by a set of distributed agents. Each user has a homeagent that provides the interface to the PageSpace and its agents. We rely on Java as the main implementation language for our agents. In the main focus of the PageSpace is the issue of coordination amongst these distributed, concurrent agents, and we explored the use of Linda-like coordination technology to solve that coordination problem.
Three issues are important in a distributed, concurrent application: How do agents synchronize their work, how do they communicate, how is activity started? Amongst the various approaches to solve this coordination problem, is one specific line of research called coordination technology that is based on the concepts introduced by the language Linda ([CG89b]).
The following characteristics make Linda-like coordination attractive for distributed applications on the Web:
Coordination technology based on Linda has a repository of shared elements and operations for the addition and withdrawal as its core. In appendix B we give more details on coordination technology and its flavours in PageSpace. In order to use this basic coordination mechanism for the Web, a Linda embedding into Java was defined for PageSpace and implemented. This system - derived from Jada ([Ros]) - forms our coordination kernel.
However, the pure data oriented style of coordination as in the original Linda-conception is not suited to support open distributed applications. It can well be used to keep state within one application, but it becomes difficult to support multiple applications that share one tuplespace.
Thus, we introduce two additional flavors of coordination styles in PageSpace. We do so by adapting the operations from two other coordination languages, that can be built on top of the repositories provided by the basic coordination technology from Jada:
The plain coordination mechanisms in Linda can be raised to a higher level by allowing declarative rules on coordination. ShaDe ([CCR96]) is an object-based coordination language. It offers a basic abstraction called the Object Space, that is similar to a tuple space with the difference that it contains objects. In fact, the Object Space is a distributed collection of objects and messages. Each object encapsulates a state in form of multiset of tuples and methods in form of rewriting rules.
For PageSpace, the most interesting feature of ShaDe is that coordination is expressed by rules. We intend to exploit such a feature to build ``coordination'' services enacting declarative cooperation laws. In the first prototype ShaDe was matched with Prolog, to obtain a distributed logic programming language. For PageSpace ShaDe is implemented on top of Jada.
The notion of services is well adapted in open distributed systems. If can also form the basis for service oriented coordination languages that support the basic interactions in service-usage and provision.
Laura ([Tol96]) is a coordination language designed for open distributed systems. Here, the tuplespace containing data is replaced with a service space containing forms describing service offers, requests, and results. The respective coordination primitives are serve, service, and result. Matching is performed on the basis of the service interface that is included in each of these kinds of forms. A subtype relation amongst these interfaces guides the matching routine in the selection of offers that match a service request.
We adopt that conception for the PageSpace and enable agents to be able to use and offer services at interfaces with Laura's coordination operations. For PageSpace, Laura is reimplemented in Java.
In the PageSpace architecture, we distinguish several kinds of agents, denoted by the names from the Greek alphabet:
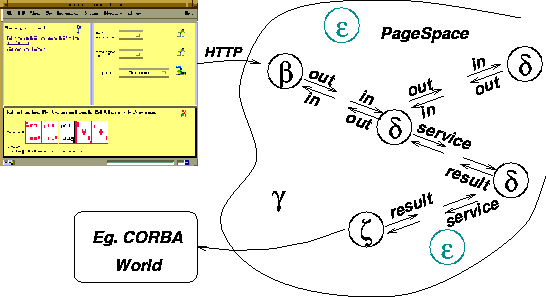
Figure 2: An application in PageSpace
In the following, we describe these kinds of agents in more detail.
The PageSpace and its application are accessible to the user from any Web browser. This browser can be located at a different machine than the actual agent that performs an application. Also, the user can move during that interaction from one browser and machine to others. Thus, it is necessary, to deal with the user interface of an application separately. Two characteristics of the user interface in PageSpace are:
For the user, it provides the interface to the PageSpace and the applications and agents therein. Figure 3 shows that interface for an example Poker application, which we call ``Alpha'', when it is manifested in the browser. This display is shown, when the user contacts his or her homeagent by retrieving a specific URL.
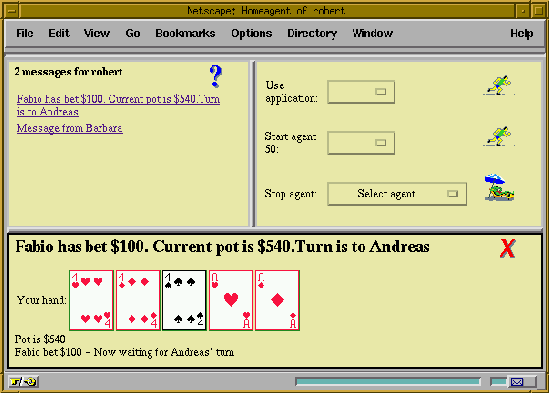
Figure 3: The interface to PageSpace for the user
Alpha consists of multiple sections. One part of the user interface does provide operations of Beta - to use applications, and to start and stop own agents in the PageSpace. A list of arrived messages shows the results of interactions with applications in the PageSpace. If the browser supports this feature, the queue is updated by a client-pull mechanism. When a message is selected, the user interface of that application is displayed in the third section of the Alpha interface.
The other ``face'' of Beta is that it is a persistent representation of the user in the net. From Alpha, a user can use applications and start agents. However, he or she does not have to be online, while the application is running. Consider as an example a groupware application in which users all around the world participate in some work.
It would be unacceptable to force the users to be logged into the PageSpace all the time, as such a distributed work is asynchronous in nature. Thus, while there is no connection to the user, Beta can still receive messages from a joined application.
Thus, Beta is looks like a complete agent to the PageSpace. However, it does only store incoming messages in a persistent store until the user retrieves them and reacts to them. In a future PageSpace, we will explore mechanisms to instruct Beta to automatically react to incoming messages, where possible.
Applications in the PageSpace are composed of agents, called ``Deltas''. In an application in use, three sorts of Deltas are involved:
Delta agents are programmed by inheriting from a class from the package pagespace.delta instead of java.object. Thereby, it is easy to enforce a certain functionality of Deltas and to provide a default behavior where possible by using the object-oriented features of Java.
The integration of legacy applications and gateways to other coordination environments can be achieved by wrapping and gateway agents that are called ``Zeta''. They are similar to Deltas in that they offer services to the PageSpace, however, they implement them by interacting with a closed application or via some middleware protocol to other middleware specific object.
The PageSpace is currently implemented as a prototype used for demonstration purposes and for the exploration of further concepts. This prototype follows the implementation strategy outlined in the following. Work remains to be done on the engineering of the platform, however, we believe that the main principles of our architecture can remain unchanged.
On each machine participating the PageSpace, one Epsilon agent is running. It can be considered the kernel of PageSpace. Each Epsilon runs on a Java virtual machine and manages multiple threads. Epsilon has several purposes:
A user accesses PageSpace via his or her homeagent that is contacted by HTTP from a browser. Thus, a Web server has to be colocated with an Epsilon. As there are more and more implementations of Web servers in Java - like Jigsaw from the W3C -, we integrate one of them as a thread in Epsilon, thus avoiding the CGI mechanism to pass information to Beta.
Beta agents are in fact implemented by a single object within the Epsilon kernel. They are parameterized with the identification of a PageSpace user. Thus, after passing a login form in which a PageSpace user name and password is entered, each user receives Alphas with the same components, but based on a different message queue, which are stored persistently in a database.
Besides the interaction with messages, the user can use applications, and start agents from Beta. Both result in the execution of a thread within the Beta object. To use an application, that thread issues the appropriate coordination operation, waits for the results, stores it in the database and terminates. To start an agent, a method of the Epsilon kernel object is invoked which starts a Delta.
Each Delta agent is executed as a thread in Epsilon. This is reasonably, as we can make use of the native interaction mechanisms within one Java virtual machine for threads, and to not have to execute multiple virtual machines on the node that participates in PageSpace.
All Delta agents have the same kernel structure as depicted in figure 4. The main purpose of it is to pass invocations of the coordination primitives on to the Epsilon kernel. Besides, the specific coordination style can be supported by prefabricated handlers, for example for the dispatching of methods when the service-based Laura operations are used.
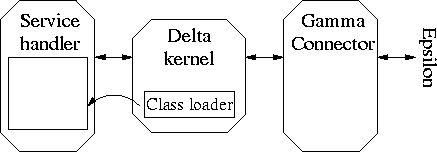
Figure 4: The logical structure of Deltas
Also, it is easy for Epsilon to manage its exception and to monitor the operation of Delta threads. Thus, Epsilon establishes the kernel of an operating system for Delta agents within a PageSpace coordinated Java virtual machine. We inherit all aspects of thread management from Java, and add the ``process'' interaction mechanisms by coordination technology.
As outlined in section 3.2, we include several flavors of coordination technology in PageSpace. All of these have in common that they are centered around the use of a shared space of element of some kind, and that some matching rule guides the coordination primitives.
Thus, Epsilon contains instances of a generic basic component, the repository. These are collections of elements of some type. Each such repository implements the specific operations of a coordination language with a specific matching routine, thus is may be optimized, but still is based on the management of a pool of elements of some type. Within the Epsilon architecture, multiple such repositories can be integrated to the internal control and data streams.
Each Epsilon kernel has to have an interface to other Epsilon agents, via which the distribution protocol is spoken. We foresee the possibility of different distribution architectures integrated via a set of interconnected sub-PageSpaces.
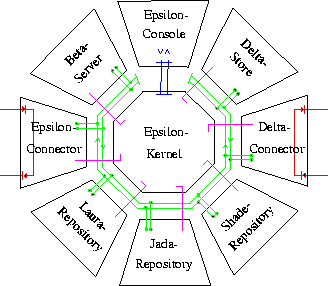
Figure 5: An outline of the logical structure of Epsilon
In middleware platforms, the issues of accessing services and naming are central. In PageSpace, we do not enforce a (distributed) registry of existing agents, but take a different approach similar to the way of accessing pages in the Web.
As Epsilon knows about all agents it is managing, it is able to provide lists of these and their interfaces. The natural way to access such a list is by providing it with the built-in HTTP server for Web access. Thus, the ``name'' of an agent for the outside world is a simple URL.
Users that want to use agents, keep their personal list of known agents - just as one does for known Web pages with a bookmark-list. This list is used by Beta to offer the use of agents and applications to the user. It can be extended by the user, and be the subject to public catalogs of agents - resembling search engines and index services on the Web.
For example, for a service-based use of the PageSpace, the interface of a requested agent has to be passed to the coordination operations. This interface is accessible from the Epsilon that manages an respective agent. Beta retrieves it via HTTP, and construct the appropriate coordination operation.
The Epsilon kernels manage and coordinate agents on one machine. For distributed applications, these kernels have to have a distribution architecture and according protocols. A special concern with such a protocol is scalability - the ability to provide efficient coordination for a platform involving a large number of machines.
The approach of establishing a shared repository of information can lead to scalability problems due to the amount of overhead for replication. We can take a flexible approach to structuring the system to overcome these problems.
We follow the approach of the Internet to scalability: The set of machines that participate in the PageSpace is organized in a loose hierarchical fashion: Locally connected machines follow a replication schema in a logical sub-PageSpace and one machine is defined as the gateway to other sub-PageSpaces. Thereby, we imitate the interconnected subnets of the Internet.
The specific organization of Epsilons within one sub-PageSpace is a local decision. Known architectures for distributed implementation of Linda-like systems include full replication of a repository to all nodes, no replication with a single, centralized repository, no replication of repositories in a ring-like organization ([Pol95]), or a partial replication as in [CG86]. As long as there is one defined node that follows a gateway protocol to other sub-PageSpaces, our architecture supports all of them. In fact, the current Jada implementation uses a centralized or fully replicated repository, whereas Laura implements a partial replication scheme.
For a gateway, a ``routing-table'' exists that instructs the gateway to which other sub-PageSpaces requests for matching elements shall be forwarded. Thus, the distribution structure can be statically or dynamically configured.
This configuration will be based on the structure and behavior of the agents within a sub-PageSpace, and supports them in their coordination requirements. The several flavors of coordination employed in PageSpace give way to several intelligent optimizations, that are to be evaluated.
The PageSpace architecture has several features that are yet to be explored. In this section, we point to two of them, namely fault tolerance and mobility. We show how these features can be introduced to the platform, and how they are enable by the design of the platform.
Failures of the Alpha agents - because of a crashing browser, or a fault in the users machine - do not affect the PageSpace at all. The failure of a Beta agent does not introduce problems, as the queue of messages for a user is kept persistent.
The Beta, Delta and Zeta agents are managed by the Epsilon kernel. Thus Epsilon has the potential to keep a log of their external interactions and to request state information from that is stored persistently. Epsilon thus can monitor the managed agents, and restart them in case they crashed with a given state. We foresee that any of the managed agents can provide a method that transfers state information to Epsilon.
In the case of an Epsilon failure, the kernel and all managed objects are lost. The log of external interactions can be used to reestablish the repositories after restart; the managed agents can be restarted accordingly.
As Delta agents interact location transparent, they are candidates to support mobility of agents within PageSpace. In order to do so, they have to be able to pass their internal state to an Epsilon, which can start it.
Deltas may want to be moved because they detect that they interact with each other and try to make the coordination more efficient by ``meeting'' at a specific location. They can be asked to move by an authoritative Epsilon, because a specific policy (workload management, or dedicated machines) applies to their current location. It has to be evaluated, what protocols are most efficient to perform such operations, and what strategies for mobility should be followed by Deltas and Epsilons.
The PageSpace is a platform to support distributed applications on top of the Web. We provide a framework that is based on the core Web technologies and Java, and add a specific approach to coordinating distributed agents in applications, namely Linda-like coordination technology. Our approach is generic towards the usage of several variants of coordination technology, as demonstrated with data-oriented, service-based, and rule-driven coordination styles. The design of the platform is enabling for a straightforward implementation of several desirable features, such as fault tolerance and mobility of agents.
Our platform is capable to support open distributed applications. In the PageSpace effort, we now focus on supporting coordinated applications in electronic commerce. Based on a prototypical implementation the platform will be engineered and validated by implementing applications from the named domain. More information on PageSpace can be found on the Web at |http://www.cs.tu-berlin.de/ pagespc|.
Acknowledgments. PageSpace has been supported by the EU as ESPRIT Open LTR project #20179. For useful discussions on electronic commerce, the authors would like to thank Carmine del Rosso, VGS, Milano.
The domain field of financial institutions (eg. banks, investment and mutual funds) is a lively, fast-growing, and important market for WWW technologies, as witnessed by the number of sites supporting financial data or research on financial applications of WWW technology.
This is because financial institutions must face new relevant factors like markets globalization, novel financial instruments, increased demand of value-added services finalized to end-users (home-virtual banking), and effective management of the related information problems. Financial institutions will be obliged to develop a new generation of distributed multiuser applications to satisfy these new demands. Internet/Intranet technology will be a powerful tool to realize this new generation of networking applications and services.
The widespread interest in the World Wide Web by the financial institutions is witnessed by the number of sites supporting financial data or research on financial applications of WWW technology. For instance, in Germany Bank24 offers home banking services over the WWW. In April 1996, Cassa di Risparmio di Spoleto inaugurated the first Internet home banking service in Italy. At the other end of the spectrum of financial services currently offered over the Internet, first sites show up, where customers can freely trade stocks using the Internet for a very competitive fee. Pointers to examples of innovative uses of WWW technologies in financial markets can be found in |http://www.wiso.gwdg.de/ifbg/finance.html|.
Technologies currently used for implementing information and operation services in financial institutions are strongly conventional and proprietary. Although they guarantee a high quality for conventional services, when new ones have to be designed, implemented, and integrated they are often not satisfactory, insufficient or too expensive to be used.
Although advanced applications on WWW already now include e-mail systems, audio-video realtime/anytime conferencing, financial data retrieval, etc., the current technology of Web middleware is not really adequate to support the services necessary to develop interactive Internet and Intranet multiuser applications. Furthermore, it is important to note that the usual kind of service banks provide is not public. In fact, it is personalized towards confidentiality and towards recognition of the customers personal financial situation and interests. Thus, there is a strong demand on providing secure, personalized, and confidential online services to customers, for example personal account monitoring and portfolio management.
An important test-bed for WWW technologies are those branches of financial institutions which need and rely upon realtime information delivery systems. An important example is the logic distribution of stock exchange data to all the geographically distributed branches of a bank. Another example is the distribution of software updates, that is an expensive operation involving several people and sometimes decreasing the quality of services offered by the branches.
Currently, branch services relying upon data coming from the central branch are typically implemented in a conventional way using a central mainframe host, which usually is already overloaded with other managing tasks on behalf of the central branch. This solution is not elegant, not efficient, and in any case not satisfactory from the point of view of information integration capabilities. Most of the current Web applications also rely on these centralized architectures to build Intranet systems and applications for elaborate financial data, which is expensive to get and difficult to manage and redistribute, because of the low level of the network technologies currently used.
The PageSpace environment may show to be a powerful tool to realize a new generation of networking applications and services in the area of financial applications. The PageSpace technologies will be studied and applied to develop solutions for several needs, including:
Linda introduces an abstraction for programming concurrent agents and defines a very small set of coordination operations. In a program based on Linda, a set of agents work on a task within a shared environment, called the tuplespace. It is a collection of tuples that contain information relevant for the application. Many variants of tuplespaces, like distributed, or hierarchically structured ones, have been studied over the last fifteen years.
Linda's primitives provide means to manipulate that shared tuplespace, thereby introducing coordination operations. A tuple can be emitted to the tuplespace by an agent performing the out-primitive. As an example, |out(<"amount",10,a>)| emits a tuple with three fields, that contain a string, an integer, and the contents of the program variable a. This operation is non-blocking.
Two blocking primitives are provided to retrieve data from the tuplespace: in and rd. Both take a template as argument - for example |in(<"amount",?int,?b>)|. A matching rule defined in Linda governs the selection of a tuple from the tuplespace: The template and the tuple must have the same length, the types of the fields must be the same, and - for a constant field (an actual) - values of fields have to be identical.
The example pattern retrieves a tuple that contains the string amount as the first field, followed by an integer, followed by a value of the same type as the program variable b. The notion ?b means that the retrieved value is to be bound to the variable b after retrieval. The difference between in and rd is that the former removes the matching tuple, while rd leaves it untouched in the tuplespace. Both operations are blocking - as long there is no matching tuple found in the tuplespace, they do not return. Linda makes no further guarantees on the selection of matching tuples and waiting operations.
It has been demonstrated ([CG89a]) that Linda is capable to express all major styles of coordination in parallel programs. in is a very powerful operation - it combines synchronization (the operation blocks until a matching tuple it found) with communication (the binding of values to program variables). Linda's operations together form a so-called coordination language ([GC92]). Combined with a sequential programming language, a new language for concurrent systems is generated. This combination is called embedding and can be implemented by changes to the programming language, by preprocessing source code, by libraries, or can be provided an extended operating system.
With the language Jada, the Linda approach has been adapted to PageSpace. Differently from other Linda-like implementations, which usually include a preprocessor, Jada is merely based on a set of classes to be used to access a tuple space.
In Jada a tuple is represented by the tuple.Tuple class and contains a set of objects. Thus, |Tuple my_tuple=new Tuple(new Integer(10),"test");| is an example of a Jada tuple It includes two actual fields; the first item is an Integer object valued 10, the second one is a String valued ``test''. To build a tuple with one formal field of type String we can write |Tuple formal_tuple=new Tuple(new String().getClass());|. Thus, a Class type used as argument in the constructor of a tuple is used to represent a formal field.
To build a tuple space using Jada we write |tuple_space=new TupleSpace();| We can share this object between multiple threads. When we want a thread to put a tuple into the tuple space we write |tuple_space.out(new Tuple(new Integer(10),"test"));|
This tuple can be later read by another (or even by the same) thread using the or the methods: |Tuple read_tuple=tuple_space.read(new Tuple(new Integer(10),"test"));| The access to the tuple space performed by the and operations is associative: these operations return a tuple matching that used as argument. Jada uses the same matching rule described above for Linda.
To support distributed programming, the classes TupleServer and TupleClient allow remote access to a tuple space. In fact, each tuple space is a shared remote resource available through a tuple space server running on some host at a specific port. This way we can run as many tuple space servers as we like in a network, so that applications can independently operate on several, distributed tuple spaces. TupleServer is a multithreaded server class which translates requests received from the TupleClient class in calls to the methods of the TupleSpace class. TupleClient interfaces with a remote TupleServer object, holding the real tuple space, and requests it to perform the , and operations.
introduces the abstraction of a service-space shared by all agents in an open system which is a collection of forms. A form can contain a description of a service-offer, a service-request with arguments or a service-result with results.
In , a service is described as an interface consisting of a set of operation signatures. The signatures describe the types of the operations in terms of their names and their argument- and result-types. It is therefore a record of function-types. A form contains a description of this interface-type for service-identification. Putting a service-request form into the service-space triggers the search for a service-offer form so that the interface-type of the offer is in a matching relation to that of the request.
In , no names are used for the identification of services or for the types of data involved in an operation. Instead, a service offered or requested is described by an interface signature consisting of a set of operations signatures. The operation signatures consist of a name and the types of arguments and parameters.
therefore puts emphasis in stating what service is requested, not on which agent is requested to perform it. A crucial point therefore is the identification of services.
In interfaces are notated in the service type language STL. In [Tol95] we formally defined a type-system which is used in the definition of the semantics of such interface definitions. This type system includes rules for subtyping and this subtyping is the key for 's identification of services: Given the interface descriptions in forms, a service offer matches a service request, if the type of the interface offered is a subtype of the one requested.
Subtyping in is defined so that a type A is a subtype of B if all values of type A can be substituted when a value of type B is requested. The ``values'' we type are services. The subtyping enables us to use a service of type A if a service of type B is requested.
A service is the result of an interaction between a service-provider and a service-user. In , two operations coordinate this interaction for the service-provider, and .
An agent that is willing to offer a service to other agents puts a serve-form into the service-space. It does so by executing , which takes as parameters the type of the service offered and a list of binding rules that define to which program variables arguments for the service should be bound.
When a is executed, a serve-form is built from the arguments. Then, the service-space is scanned for a service-request form whose service-type matches the offered service by being a supertype. The provided arguments are copied to the serve-form and finally bound to program variables. blocks as long as no matching request-form is found.
After performing the service requested, the service-provider uses to deliver a result-form to the service-space. A result-form is built which consists of the service-interface and - depending on operation - a list of result values according to the binding list. The agent is responsible to store the results of the service properly in those variables. The operation is performed immediately and the form is put into the service-space. An agent offering services usually operates in a loop consisting of the sequence -perform the service-.
An agent that wants to use a service has to execute 's third and last operation, . Its arguments are the service-type requested, the operation requested, arguments for the operation and a binding-list.
When executing , two forms are involved: a service-put form and a service-get form. The first is constructed from the service-interface and the arguments and then inserted to the service-space. If another agent performs a -operation and the service-put- and serve-forms match, the arguments are copied as described above and the service-provider starts processing the requested operation.
The service-get form is constructed from the service interface and the binding list for the results. Then, a matching result-form is sought in the service-space and - when available - the results are copied and bound to the program variables. When the request-form is entered to the service-space, it is matched with some serve-form. When the result-form is retrieved, the results are bound to program variables of the requesting agent.
The interaction of agents coordinating services with consists either of putting a request for a service to the service-space, finding a matching offer form and copying of arguments or of trying to get the results of a service, by finding a matching result-form and copying of the results. This interaction is uncoupled, as service-provider and -user remain completely anonymous to each other.
For rule based coordination, the coordination language Shade has been embedded to Java and uses the coordination primitives of Jada. A Shade program is a collection of classes; each object in a Shade application is an instance of a class. Each class contains a set of rules which define the behavior of the objects which are instances of that class. A class can be extended using inheritance, i.e. its behavior can be modified adding new rules. Objects are class instances and have a state. A state change can happen when a rewriting rule is applied to the object state or when an object receives a message.
Since it denotes a rewriting rule, a Shade method has a head and a body. The head is used to trigger the method itself and gets items from the object state, while the body puts items in it. Semantically, each object is a tuple space with associated rewriting rules. When a rule is activated, by satisfying a guard which can remove matching items from the tuple space or simply check for their existence, an action is performed. The action is one of writing items in the object's tuple space, writing items in other objects' tuple spaces (i.e. sending a message), or creating a new object.
Shade is especially useful for coordinating distributed objects. The action of writing in other objects' tuple spaces is performed by a special form of message passing. A message's address is a pattern; messages are delivered to each object whose name matches the given pattern. This way we can easily express with the same basic mechanism point-to-point, multicast, and broadcast communications. Messages are not just associative, they are also persistent: each time a new object is created, it receives all messages generated before its creation whose addresses match its own name.
Each object in Shade has a name, a class, and a state. The name is the pattern used to deliver messages. The type defines the object behavior (a Shade program is indeed a collection of classes definitions, where a class is a set of rules). The state is the contents of the multiset associated to the object, implemented as a tuple space. A Shade/Java program consists of a set of classes; each class includes a set of methods composed from a head and body part.
The head is a transaction over the local tuple space. If all operations can be performed, they commit and the body is executed. The head can contain the following operations: