A Modular Framework for the Creation of Dynamic Documents
Abstract
| |
In this position paper a modular framework for the creation of dynamic documents is proposed. The motivation for this framework is to make use of the World Wide Web as both a source and a target for dynamic documents. To reach this goal we propose the use of an information store as an intermediate layer between retrieval and integration of document fragments and semantic information. By hiding away retrieval from integration even existing dynamic document creating applications can make use of already available and forthcoming information retrieval and natural language processing systems.
| |
Introduction
Whenever a more or less famous person of our times and business enjoys the world with his visions about what the brave new networked hypermedia future will look like, the on-the-fly creation of documents is among the promises made [6, 10]. The idea of dynamically composing a document is indeed very exciting. It even gets more exciting if the resulting document not only exactly matches a user's request but even is adapted to his background and personality.
Most of these visions of dynamic documents are heavily influenced by the enormous growth of the World Wide Web. The Web is an ideal base for dynamic documents because it can be used as both source and target:
- The world's largest search engine - Altavista - claims to have indexed more than 100 million documents. These are 100 million information sources containing information to be extracted and reintegrated. These are 100 million documents consisting of a billion fragments to be split and restructured like the pieces of a jigsaw. These are 100 million documents covering a million of topics and providing an uncountable number of information which could be extracted, analysed, and transformed into big knowledge bases.
- The World Wide Web has means and standards for document presentation (HTML, Java, ActiveX, etc.), document exchange (HTTP), document linkage (hyperlinks), and dynamic document creation (CGI, ASP).
Most dynamic document systems make intensive use of the Web's target functionality. Only few of theses systems makes use of the Web as a dynamic and large fragment and/or information source. The major drawback of ignoring the Web's source functionality is the restriction to a set of well defined knowledge domains for which proprietary structural and semantic information is available.
In this position paper we propose a generic framework for the creation of dynamic documents that allows for the integration of powerful (not only web based) information retrieval systems. By adding the dynamic retrieval of fragments, semantic and factual information, dynamic document systems can become useful tools for learning and information about any topic a user is interested in.
Retrieval vs. Integration
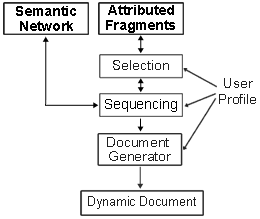 Figure 1 gives a coarse impression of the architecture of most dynamic document systems. The most important building blocks are
Figure 1 gives a coarse impression of the architecture of most dynamic document systems. The most important building blocks are
- some kind of semantic structure (e.g. a semantic or a conceptual network) providing information about the knowledge domain covered by the system,
- a collection of fragments (canned texts, phrases, images, etc.) needed to put together the surface of the resulting document,
- a selection module to select the most appropriate among the fragments,
- a sequencing module for discourse planning and structuring, and
- a document generator to integrate the selected and sequenced fragments or phrases into a set of HTML files.
Whether and how these building blocks are implemented depends on the kind of dynamic document system:
- With a natural language generating system like ILEX [8] the fragment store contains a lexicon of phrases. Sequencing is named text planning and makes use of a network of facts. The document generator is implemented as a surface realisation component.
- Fragment based bottom-up oriented systems (non-planning approaches doing selection first) like i4 [3] don't require a semantic network. Instead the semantic information needed for selection and sequencing is kept with each fragment. This causes the demand for the fragment store to hold both fragments and meta-data (attributes in this case). The selection module picks the most appropriate among the fragments and passes them to the sequencing module to create the discourse structure. Integration of fragments into HTML code is again task of the document generator.
- Fragment based top-down approaches (discourse planning adaptable hypertext systems) like ELM-ART [2] use a simple conceptual network for discourse planning. For each concept that is part of the resulting document a providing fragment is selected. All selected fragments are sequenced and integrated into a set of HTML files.
All of these approaches have in common that at least the fragments and/or the semantics have to be provided manually:
- "Hand-entered information includes type hierarchies for jewels and designers, ..." [8]
- "This work has made use of an online encyclopedia." [7]
- "The first step is to collect a set of mediaobjects and provide meta-information about them. This is nearly the only task that has to be performed manually." [4]
- "A special graphical editor for concept structures allows the creation of concepts, connecting them among each other with various types of semantic relations ..." [12]
The major drawback of the demand for hand-entered information is the restriction to a well defined knowledge domain. E.g. if a user wants to learn something about climate on mars he has to rely on Altavista, because none of the dynamic document systems available contains semantic information and/or fragments about the solar system.
A second drawback is the fixed nature of the hand-entered data. Manual maintenance of a semantic network about a rapidly changing topic (e.g. the German tax system or the Italian government) is nearly impossible and will in the long run result in non-current documents. Further more many domains allow for different interpretations of facts (e.g. the Clinton-Levinsky case or some economic topics like the European Monetary Union). A static semantic structure can usually only reflect a single interpretation, which prevents an objective, balanced description of "facts".
To overcome these problems, the semantic structure as well as the document building fragments should be retrieved dynamically. By doing so arbitrary user requests could be answered with dynamic documents. Even rapidly changing and highly subjective topics could be handled because each time a user requests information about such a topic a new, current, and adapted semantic network would be set up.
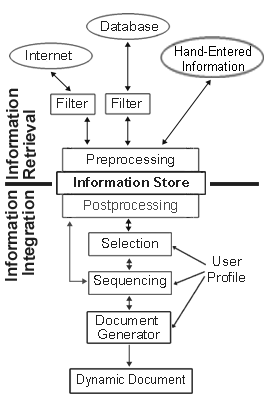 The figure on the right shows how such a framework for adaptable, dynamic documents that makes use of dynamic fragment and semantics retrieval could look like.
In NLG and top-down oriented scenarios, data from various sources is first collected and analysed to set up a semantic network. The semantic network is hidden within an information store to provide a layer of abstraction between retrieval, selection, and sequencing. Documents matching parts of the semantic network are retrieved, split, normalised and stored within the information store, too. Based on these information discourse planning, selection, sequencing and document creation is done using any of the existing approaches. For a bottom-up oriented scenario without discourse planning, documents matching some domain specific queries are retrieved and analysed. Then these documents are split, indexed, and stored in the information store. In parallel a fragment graph is set up within the information store that is used for selection and sequencing. If a semantic network is available for the given knowledge domain, semantic document analysis can be omitted, because the fragment graph can as well be set up using this information.
The figure on the right shows how such a framework for adaptable, dynamic documents that makes use of dynamic fragment and semantics retrieval could look like.
In NLG and top-down oriented scenarios, data from various sources is first collected and analysed to set up a semantic network. The semantic network is hidden within an information store to provide a layer of abstraction between retrieval, selection, and sequencing. Documents matching parts of the semantic network are retrieved, split, normalised and stored within the information store, too. Based on these information discourse planning, selection, sequencing and document creation is done using any of the existing approaches. For a bottom-up oriented scenario without discourse planning, documents matching some domain specific queries are retrieved and analysed. Then these documents are split, indexed, and stored in the information store. In parallel a fragment graph is set up within the information store that is used for selection and sequencing. If a semantic network is available for the given knowledge domain, semantic document analysis can be omitted, because the fragment graph can as well be set up using this information.
Information sources may be accessed through filters. Possible filters for databases could be anything from query languages up to complex information integration systems for combining the contents of many different databases. Among filters for WWW based information sources could be search engines (e.g. Altavista), query languages (e.g. WebSQL [13]), clustering and classification systems (e.g. SONIA [11]), or any combination of these services.
Dynamic retrieval of semantic structures cannot be completely automated using current technology. For this reason hand-entered information can be added to the information store. By hiding hand-entered information inside
the information store existing dynamic document systems can easily adapted to the proposed modular architecture.
This directly leads to the main idea behind the proposed architecture: Starting with only manually provided information the content of the information store is step by step attributed, enriched, and extended by automatically retrieved information and fragments. E.g. if a hand-entered semantic network is given, it should be possible to dynamically retrieve a high percentage of the documents, fragments, or phrases needed by making use of existing IR technology. Especially web sites already providing meta-information about their contents and structure (e.g. by using Dublin Core [5] or Web-Schemes like Araneus [1]) could be good sources for this kind of information. Further more, existing semantic structures can be used transparently by accessing them through the generic interface of the information store. Even if all semantic structures and fragments have to been entered manually, the framework supports the transparent integration of services like language detection, quality measuring, document fragmentation, etc.
Another advantage of this modular architecture is the possibility to logically and physically distribute the various services, e.g. by using a CORBA-like infobus architecture. Mapped to the CORBA terminology, selection, sequencing (discourse planning), and document creation would be application objects, the information store a common facility, and source wrappers, filters and additional services common object services. Communication between the services would be done through an object request broker.
The Information Store
The information store acts as an intermediate layer between the information retrieval and information/fragment integration part of a dynamic document system. Its main purposes are to
- decouple these layers from each other by providing an abstract interface for accessing semantic information as well as concepts, fragments or phrases
- enable the integration of services like language detection or quality measuring (e.g. [8])
- allow the externalisation of problems like pricing and authentication
The most important part of the information store is its interface. How semantic structures and fragments are stored (and even if they are stored at all) and how they are encoded internally is completely implementation dependant. The information store may either be implemented as a real store or just as a cache. If it is implemented as a cache it is just used as an abstraction layer, e.g. to wrap an existing semantic network or to integrate fragments from different sources.
The two kinds of objects maintained by the information store are fragments and concepts. Fragments may be of any size and type ranging from single words or phrases up to large, mixed-type documents and digital video. Outside the information store each concept and fragment is just a set of name-value pairs (attributes). Relationships between any two objects (object mappings) can be assigned attributes as well in order to set up semantic networks, fragment graphs, and indices.
Interfaces
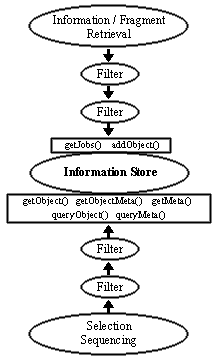 The figure on the right shows how the information store is used to separate information and fragment retrieval from integration. Various filters can be placed between the information store and the other building blocks either to provide additional functionality or to wrap interfaces. What filters are needed and used depends on the retrieval system, the additional services required, the dynamic document system, and the knowledge domain.
The figure on the right shows how the information store is used to separate information and fragment retrieval from integration. Various filters can be placed between the information store and the other building blocks either to provide additional functionality or to wrap interfaces. What filters are needed and used depends on the retrieval system, the additional services required, the dynamic document system, and the knowledge domain.
The information store should at least contain seven standardised interfaces - two on the retrieval side and five on the integration side:
- getJobs()
- Return a list of what kind of fragments, facts, or semantic information is currently required.
- addObject()
- Add an object or an object mapping to the information store. The content, encoding, price, and other attributes of the object must be described by attributes.
- getObject()
- Read an object or object mapping from the information store.
- getObjectMeta()
- Read only a certain attribute's value from the information store.
- getMeta()
- Get meta data about all objects. These meta data may range from the number of objects stored up to a conceptual network created dynamically from all objects within the information store.
- queryObject()
- Test whether a certain object or mapping exists within the information store. The description of the desired object should be based on meta data describing the object.
- queryMeta()
- Test whether a certain kind of global meta data can be provided by the object store.
The only purpose of the two query interfaces is money. The idea is that any call to one of the query interfaces is for free, while retrieving objects or meta data from the objects store is potentially not.
Meta Data
Each object or mapping within the information store is described by attributes. The values of these attributes can partly be provided by an information retrieval system, partly be calculated by various filters or the information store itself, and partly be set by hand.
What kind of meta data is available depends on the type of the object. E.g. concepts could be described by synonyms, grammatical and morphological rules, domain specific information, etc. Fragments may be attributed by
- their contents (e.g. required and provided concepts or a conceptual network encoded as a set of concept-concept mappings)
- formal aspects (e.g. type, size, age, language, etc.)
- copyright information defining by whom, for what purpose, and how the object may be used
- authentication information defining when, where and by whom the object was retrieved and how and by whom the originality of the object was proven (or can be proven).
- pricing information stating who has to pay what amount of money to whom for using the object.
Mappings of concepts to concepts are used to describe semantic or conceptual networks. Possible attributes could be the kind and direction of relationship between the two objects. Mappings of fragments to fragments are required by bottom-up oriented, fragment based systems in order to set up fragment graphs. For systems that do discourse planning based on semantic structures mappings from concepts to their providing fragments are needed. All of these mappings are mainly attributed by various weight specifiers, e.g. how a concept is explained by a certain fragment.
In order to make meta data as extensible and flexible as possible some of the attribute's names and semantics should be taken from existing standards (e.g. Dublin Core [5]), some have to be standardised, and some should be left open to the implementers of the retrieval and the integration parts.
Filters
The functionality of the information store can be extended by filters. Retrieval side filters are mainly used to calculate additional meta data while integration side filters provide additional services like pricing, type conversion, or formatting.
The main idea of providing the ability to add filters to the information store is to make use of already available systems (e.g. language detection, document fragmentation, stemming, keyword extraction) and to externalise open problems (e.g. pricing).
Acknowledgements
This work is supported by the German Research Network as part of the DIALECT/DIALERN project and by the German Research Society as part of the Berlin-Brandenburg Graduate School in Distributed Information Systems (DFG grant no. GRK316)
References
- Araneus Homepage, http://www.dia.uniroma3.it/Araneus/index.html.
- Brusilovsky, P., Schwarz, E., and G. Weber, ELM-ART: An intelligent tutoring system on World Wide Web. In 3rd International Conference on Intelligent Tutoring Systems, ITS-96, Montreal, June 1996.
- J. Caumanns, "A Bottom-Up Approach to Multimedia Teachware", In 4th International Conference on Intelligent Tutoring Systems, ITS-98, San Antonio, 1998.
- Caumanns, J. and H-J. Lenz, "Hypermedia Fusion - A Document Generator for the World Wide Web", In IEEE Multimedia Systems 99, ICMCS99, Fierence, June 1999 (to appear).
- Dublin Core Home Page, http://purl.oclc.org/dc/.
- B. Gates, The Road Ahead, Viking Penguin, New York, 1995.
- Hearst, M., Kopec, G., and D. Brotsky, "Research in Support of Digital Libraries at Xerox PARC." Available as http://www.dlib.org/dlib/june96/hearst/06hearst.html.
- Milosavljeciv, M. and J. Oberlander, "Dynamic Hypertext Catalogues: Helping Users to Help Themselves." In 9th ACM Conference on Hypertext and Hypermedia, HT'98, Pittsburgh, June 1998. Available as http://www.cmis.csiro.au/Maria.Milosavljevic/papers/ht98/.
- Naumann, F., Leser, U., and J.C. Freytag, Quality-driven Integration of Heterogeneous Information Sources, Technical Report HUB-IB-117, February 1999. Available as http://www.dbis.informatik.hu-berlin.de/~naumann/HUB-IB-117.ps.gz
- N. Negroponte, Being Digital, Knopf, New York, 1995.
- Sahami, M., Yusufali, S., and M.Q.W. Baldonado, "SONIA: A Service for Organizing Networked Information Autonomously." In Third ACM Conference on Digital Libraries, DL98, Pittsburgh, June 1998.
- J. Vassileva, "Dynamic Course Generation on the WWW", In Workshop on Intelligent Educational Systems on the World Wide Web, Kobe, August 1997.
- WebSQL Home Page, http://www.cs.toronto.edu/~websql/