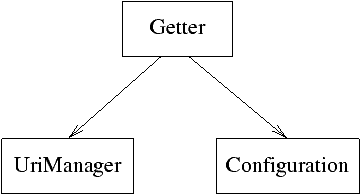
Vengono forniti tre moduli OCaml, il cui grafo delle dipendenze
è mostrato in figura 4.1
Figura 4.1: Grafo delle dipendenze per i moduli dell'implementazione del getter come modulo OCaml
Il primo modulo, chiamato UriManager,
fornisce il tipo di dato astratto uri, la funzione eq
per determinare l'uguaglianza fra uri e due funzioni di conversione fra il
tipo di dato astratto e la sintassi concreta, chiamate string_of_uri
e uri_of_string. La signature del modulo è la seguente:
type uri
val eq : uri -> uri -> bool
val uri_of_string : string -> uri
val string_of_uri : uri -> string
Il secondo modulo, chiamato Configuration, ha la seguente signature:
val tmpdir : string
val indexname : string
val servers_file : string
val uris_dbm : string
val dest : string
dove servers_file è il path assoluto del file descritto al punto
3, uris_dbm quello del file Berkeley DB descritto al punto 4,
indexname il nome del file descritto al punto 2, dest
il path del cache e tmpdir il path del directory da utilizzare
per la creazione di file temporanei. Il modulo deve essere implementato in
modo da leggere i parametri da un file XML specificato in qualche modo
dall'utente.
Il terzo modulo, chiamato Getter e dipendente dai precedenti, fornisce
esclusivamente l'implementazione dei due metodi update e
get, basata sulle decisioni prese nei precedenti punti. La signature
del modulo è la seguente:
(* get : uri -> filename *)
val get : UriManager.uri -> string
(* synchronize with the servers *)
val update : unit -> unit
Il metodo update si occupa di rigenerare il database contattando tutti i
server elencati nel file di configurazione. Il metodo get cerca in cache
il file il cui URI viene dato come parametro. Se non lo trova, lo scarica
utilizzando l'URL a cui l'URI è associato nel database e ne mette una
copia in cache. In entrambi i casi ritorna il path assoluto del file in
cache.