The format is designed to be consumed by programs, and so it is relatively terse and simple to parse, although meaningful ASCII byte-sequences have been used to make debugging and programming easier. The omission of some features, like the ability to rearrange white-space within data enable the current form of VTML to be used directly with binary data. As we are currently applying VTML to the management of text, and as the operations supported in the current version are best suited to stream-oriented data, we will refer to the data managed by VTML as "text." Despite this teminology, any byte can be directly represented in a VTML document.
In order to allow for a wide range of versioning styles, two different representations are provided, which are as much as possible equivalent to each other. An internal representation adds versioning information to the text in the proper position of the text. Support for deleted text and for incompatible situations in different branches of the version history is granted. An external representation allows the creation of autonomous change lists (deltas) that can be managed (stored, sent, parsed, etc.) separately. With a few exceptions to be noted later on, the two representations are equivalent and can be freely mixed.
An important work style that we wanted VTML-based systems to support is the one which is completely hidden to the disinterested user, requiring no intervention, decisions and even awareness of its existence during "normal" use. This implies freeing the users from worrying about freezing styles, version identification and numbering, consistency catching and management. Similarly rigorous and controlled "check out, edit and check in" cycle is also a burden for casual or emergent collaborations and creative writing. In many real life situations, "opportunistic editing" is a part of natural collaboration [1]. In some cases, without thinking, a user could open and edit a local copy of the document that hasn't been previously explicitly checked out from the server. In other cases, the urgent need to record new ideas cannot wait for another writer to release a lock on the document. In other cases, a central storage system would need to compare and join variants of the same document by different authors with versioning unaware editors. A VTML-based versioning system, therefore, should be able to support all these events, allowing for sudden check ins, parallel check outs and automatic detection of the contribution.
This implies a number of potential features of VTML-based systems:
A sequential data format allows for three kinds of operations, from which all others can derived: insertion, deletion and modification. An append operation, for instance, is an insert at the end, a move operation can be mapped as a sequence of a deletion and an insertion, and so on. Modifications refer to changing an attribute of an atomic object (e.g. the value of a field in the corresponding record), without modifying its identity. Since modifications make little sense in text data format (for instance in HTML even the attributes of the characters are part of the text itself), we can restrict ourselves for the moment to two basic operations: insertions and deletions. Where modifications are required, we represent them as the paired deletion of old data and insertion of replacement data.
VTML internal representation is a somewhat SGML-like language that wraps modified text with information about the context in which a change happened. VTML's external representation is a sequence of change operations. Attributes stored with every change also contain contextual information to correctly locate a change relative to particular point(s) in a particular version.
Additonal information, besides the information required to record a change, can be included as additional attributes. These "application attributes" are syntactically distinguished from those VTML defines, which are required to interpret a change. For instance, the published version of VTML [2] had four additional fields for the name of the author of the change, the date, some comments and the classification of the change. VTML no longer prescribes such specific application attributes, but offers a general way for an application to attach meta-data to changes. Since VTML is a change-tracking language, every single change in a document needs to mention all the relevant attributes, therefore some sharing mechanisms are provided in order to allow smaller VTML files that include the same information.
VTML notation is not part of the data it describes, and it lies on a different level than the language it versions (e.g. HTML or plain text). The authors carefully considered the possibilities of simply amending a tagged data format like HTML to include versioning information. This did not lead to an acceptable solution for a number of reasons:
A VTML file is composed of "elements" described by tags. Most elements may nest, containing data possibly mixed with other tag content. The examples in the following sections use a syntax very similar to that in our WWW IV paper [2]. We are now seriously considering a revised syntax that is a little less readable, but considerably less verbose and easier to parse with ad hoc parsers.
The VTML syntax we employ here uses curly brackets "{}" to delimit tags, and the ASCII backslash (or solidus) to escape curly brackets and itself in data content. A lexical scanner for VTML operates in two modes, Data Mode, and Markup Mode. In Data Mode escaped bytes are unescaped, and other bytes are accumulated. An unescaped open parenthesis signals a change to Markup Mode (which then tokenizes tokens in a way that is suitable for VTML tag recognition). In markup mode, white space serves as a token separator, in much the same way as it does in C, allowing the introduction of arbitrary whitespace without affecting processing. In Data Mode, however, all characters are literal and significant.
The fact that VTML operations are defined in terms of exact byte sequences means that VTML processors need not know the format of a file to work with it. We do not intend that VTML processors for textual formats be required to preserve whitespace in data if it is known that doing so is not necessary. But this kind of processing is only possible for special data types that a processor has additional information about.
All change commands that are described with internal tags are stored within a single VTML block, while external tags may be stored in as many blocks as needed. Applications that require support for both internal and external changes in a single file may concatenate multiple blocks together. In many uses of VTML, for example, in data transport and update protocols, only one type of block will be needed in a given transaction.
Attributes for the VTML tag are:
- CVERS (Current VERSion): specifies the "default" version that is to be displayed when no other specification is given by the user.
- NAME: specifies a name for the document. This may or may not be its URL or any other valid string. External tags will refer to this name in the "source" attribute to identify their context.
{ATTR ID=1 ref=1 vers=1 _author="Ron" _date="Aug. 15, 1996"}
{INS ATT=1}Something{/INS}
is equivalent to:
{INS ref=1 vers=1 _author="Ron" _date="Aug. 15, 1996"}Something{/INS}
Tags may specify their own additional attributes. When determining the set of attributes of an element, attributes specified on the element override any values set on any ATTR tag referenced. If an ATTR tag has an ATT attribute, this process may repeat. Thus, in:
{ATTR ID=1 ref=1 vers=1 _author="Ron" _date="Aug. 15, 1996"}
{INS ATT=1 _author="Fabio"} Something {/INS}
the author is Fabio.
Attributes for the ATT tag are:
- ID: an unique attribute, which specifies the identifier used by the other tags with the ATT attribute. Every attribute stored in the ATTR tag is literally substituted in all tags using that ID.
Additional attributes:
- All the attributes available in the INS, DEL, EXTINS, EXTDEL and USROP tags.
Attributes for the INS and DEL tags are:
- ATT: it refers to a list of common attributes contained in an ATTR tag.
- REF: a reference identifier used by a USROP operation. An identifier for this particular change within the version. This identifier allows the naming of individual changes. If more than one VTML tag has the same REF value, then all of those tags should be considered as a single operation by an application. Ref values, like version identifiers, must be persistent, so that externally stored USROPS remain valid.
- VERS: the version identifier in which the change happened. Version identifiers follow some precise rules that will be dealt in section 6.4
Attributes for the EXTINS and EXTDEL tags are:
- All the tags available in the INS and DEL tags.
- SOURCE: specifies the name of the document the tag is an operation on, as contained in the NAME attribute of the VTML tag.
- POS: specifies the position within the version at which the operation must take place. A discussion item is whether the address specified in the (n+1)th operation depends on the previous n operations or if it refers to a history-independent addressing mechanism. More on this in section 8.
- LENGTH: for EXDEL tags, specifies the length of the text to be deleted. Engines should rely on the length attribute to determine the text to be ignored. An additional content can be added for descriptive purposes only.
Besides the attributes also available in INS and DEL tags, USROP accepts two attributes that determine the effect of the USROP:
- INCLUDES specifies a list of versions and change REFs that should be included in the new version, regardless of their position in the version tree. Mention of a version without specifying a change REF includes all the changes in that version, and only those changes - ancestral versions are not automatically included.
- EXCLUDES specifies a list of versions and change REFs that should be removed from the new version, regardless of their position in the version tree. Exclusion of a change takes precedence over its inclusion.
First version: Ron inserts the string: "The <B>quick brown</B> fox jumps over the <I>lazy</I> dog."
Second version: David substitutes "quick" with "speedy", and removes "<I>lazy</I>": "The <B>speedy brown</B> fox jumps over the dog."
Third version: Ron substitutes "brown" with "red" and inserts "sleepy" before "dog": The <B>speedy red</B> fox jumps over the sleepy dog.".
For reasons known to the server, version 1 and 2 are stored together with the internal markup, while version 3 is stored externally (maybe the server hasn't had the time yet to join the new version).
Separately, Fabio opened the document immediately after version 2 was stored on the server and made some personal modifications: he substituted "jumps over" with "is not chaught by" and inserts "Today" at the beginning of the sentence: "Today the <B>speedy brown</B> fox is not caught by the dog." The document is saved on Fabio's personal filespace, and is not accessable by the central server.
Ron gets version 1, 2 and 3 from the server, and receives an e-mail from Fabio asking him to integrate his contributions. The following is the set of VTML blocks he receives from the server:
{VTML NAME="Hunting" CVERS=2 _AUTHORS="Ron, David"}
{ATTR ID=1 vers=1 _author="Ron" _date="Aug. 15, 1996"}
{ATTR ID=2 vers=2 _author="David" _date="Aug. 16, 1996"}
{INS ATT=1} The <B>{INS ATT=2} speedy {/INS} {DEL ATT=2} quick {/DEL}
brown </B> fox jumps over the {DEL ATT=2} <I> lazy </I>
{/DEL} dog. {/INS}
{/VTML}
{VTML NAME="Hunting" CVERS=3 _AUTHORS="Ron, David"}
{ATTR ID=1 SOURCE="Hunting" VERS=3 _author="Ron" _date= "Aug. 18,
1996"}
{EXTDEL ATT=1 POS=15 LENGTH=5}
{EXTINS ATT=1 POS=15}red{/EXTINS}
{EXTINS ATT=1 POS=42}sleepy {/EXTINS}
{/VTML}
and this is what he received from Fabio through e-mail:
{VTML NAME="Hunting" CVERS=3 _author="Fabio, Ron, David"}
{ATTR ID=1 SOURCE="Hunting" VERS=3 _author="Fabio" _date="Aug. 17,
1996"}
{USROP ATT=1 REF=2 NAME="SUBSTITUTION"}
{EXTDEL POS=29 LENGTH=10}jumps over{/EXTDEL}
{EXTINS POS=29}is not caught by{/EXTINS}
{/USROP}
{EXTINS ATT=1 POS=1}oday t{/EXTINS}
{/VTML}
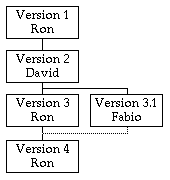
Ron pastes Fabio's version (with the VTML-aware client). The first problem is that both version claim to be version 3, since both were created from version 2 in absence of other derived versions. Ron needs to decide whether should Fabio's version remain in the main branch of the version tree, or his own. He decides on his own. This affects the numbering of the versions (Fabio's version gets renumbered and becomes 3.1). Then Ron merges Fabio's contributions in a new version: he accepts the substitution of the verb, but NOT the insertion of "Today".
This is the structure of the version tree:
The client easily generates the following internal representation:
{VTML NAME="Hunting" CVERS=CURRENT AUTHORS="Ron, David, Fabio"}
{ATTR ID=1 ref=1 vers=1 author="Ron" date="Aug. 15, 1996"}
{ATTR ID=2 ref=2 vers=2 author="David" date="Aug. 16, 1996"}
{ATTR ID=3 ref=3 vers=3 author="Ron" date="Aug. 18, 1996"}
{ATTR ID=4 ref=4 vers=3.1 author="Fabio" date="Aug. 17, 1996"}
{ATTR ID=5 vers=CURRENT author="Ron" date=NOW}
{USROP ATT=4 NAME="Substitution" REF=6 INCLUDES="5"}
{USROP ATT=5 NAME="Merge" EXCLUDES="7"}
{INS ATT=1} T{INS ATT=4 REF=7}oday t{/INS}he <B>{INS ATT=2} speedy
{/INS} {DEL ATT=2} quick {/DEL} {DEL ATT=3} brown {/DEL} {INS ATT=3} red {/INS}
</B> fox {DEL REF=5} jumps over the {/DEL} {INS REF=5}is not caught by
{/INS} {INS ATT=3} sleepy {/INS} {DEL ATT=2} <I> lazy </I> {/DEL}
dog. {/INS}
{/VTML}
which can either be sent as such to the server or divided again into elements and sent separately. When the server receives the document, will substitute the CURRENT value with the appropriate version number (in this case, 4) and NOW with the date and time of the reception.
Insertions naturally form a tree structure in the documents: whenever a user adds some more text at a specific position, a new tag is inserted in the correct position and a new leaf of the hierarchy is formed. Since it is only possible to insert data within existing text, the context of an insertion is always a version that is an ascendant of the current one. For instance:
{INS ATT=X} The <B>{INS ATT=Y} speedy {/INS} brown </B> fox jumps over the <I> lazy </I> dog. {/INS}
implies that version Y is a descendant of version X (although not necessarily a direct one (first level son)). This allows the parser to ignore whole subtrees of the text when they are surrounded by an INS of a version which is on a different branch than the one being displayed. INS tags of independent versions can be stored side-by-side in any order without differences (this implies that there is not a canonical form for VTML documents).
Deletions must also nest correctly with respect to the insertion tree. This means that in some circumstances editing clients will be forced to make more than one VTML tag that corresponds to a single user deletion operation. For instance:
Version x: The speedy fox and the lazy dog.
Version y: The speedy fox and the lazy dog.
would have to be represented as
{INS ATT=x} The speedy {DEL ATT=x} fox {/DEL}{DEL ATT=y}{DEL att=x and{/DEL}{/DEL}{DEL ATT=y} the {/DEL}lazy dog.{/INS}
The deletion in version y had to be split into two operations. However, since changes can be unified by sharing a change REF, the nesting constraint does not reduce the expressiveness of the language.
External markup overcomes simply and elegantly all questions about nesting, overlapping, etc., and it allows a simple and direct method of building versions.
Positions and length are expressed using any sufficiently fine-grained method, such as byte-counting. Care must be taken if the server or client may act on the character sequence in VTML files, as this could disrupt the byte offset of some externally stored modifications.
The USROP operation also makes it possible to define higher level operations that are correctly interpreted by a sophisticated tool, without having to define new tags in the language. It is thus possible to define substitutions, moves, merges, sorts, etc., and represent their effects by a collection of individual INS and DEL operations.
The REF attribute is used to attribute different change operations to the same USROP. In fact, each USROP is connected to the atomic operations it is composed of by either:
- containing them in a hierarchical way (handy for external tags and/or adjacent ones),
- listing their REFs in their includes and excludes attributes.
Versions of a document in VTML rigidly adhere to a tree structure. Even merging, as we implement it, does not disrupt the tree structure, since we require that a merged version descends directly from only one of the merged versions, having a different and special relationship with the other ones. This allows us to assert that version numbering is a kind of tree numbering. Ease of use requires that the chosen numbering schema allow simple and fast algorithms to determine basic facts about nodes, such as who is the direct ancestor, who is the n-th sibling, etc.
We list four numbering schema that could be used in VTML, which we call outline numbering, reverse outline numbering, L-shaped numbering and explicit naming. We believe that only one of them should be selected and the others discarded. In section 8 we will discuss reverse outline and L-shaped, which constitute in our view the best potential candidates.
The ones that are most interesting to us are connected to collaborative writing on the World Wide Web, especially the ill-formed situations, in which there is no entity "in control of" the editing and change operations, and no established way of collaborating enforced on the team of users.
In the first scenario we envision VTML-aware editors interacting with a VTML server (it could, for instance, be a standard HTTP server with a CGI application to provide VTML functionalities) in order to request and edit a versioned resource. In this scenario, the client is used for most of the versioning functions:
In this scenario, the server application is only required to provide the correct check-in dates and version numbers, to store the received version appropriately, and, in some cases, to update the setting for the "default" version. The operation of inserting the changes specified in the new versions within the stored copy of the document is called "joining", is automatic, and can be done at any time: during check in, or in batch mode as soon as the server's load is sufficiently low, or just before the successive check out, or even on the client itself just before the new edit.
A second scenario has a VTML-unaware browser interacting with a VTML-aware server in order to request and display a versioned resource. Since VTML is not known to the client, the VTML serverside application will generate the HTML of the requested version and deliver it to the client. Since we assume that every version has its own URL, it is possible to access every individual version by specifying the appropriate URL. Otherwise, lacking any version specification, the default version is returned.
A third scenario has a VTML-unaware editor interacting with a VTML-aware server in order to request and edit a versioned resource. Since VTML is not known to the client, the VTML serverside application will generate the HTML of the requested version (of the default version if none was specified). The editor therefore just manages and edits plain HTML. After the document has been sent back to the server, the VTML serverside application will notice that the content has changed. It will diff the new content with the original version, will create the change operations that describe the new content, and will update the stored copy with the new data properly deciding the new version number, check-in date and the new default version. These operations can be done at any time, even in batch mode.
{VTML NAME="Hunting" VERS=3 author="Fabio, Ron, David"}
{ATTR ID=1 SOURCE="Hunting" VERS=3 author="Fabio" date="Aug. 17,
1996"}
{USROP ATT=1 REF=2 NAME="SUBSTITUTION"}
{EXTDEL REF=1 POS=29 LENGTH=10}jumps over{/EXTDEL}
{EXTINS REF=2 POS=29}is not caught by{/EXTINS}
{/USROP}
{EXTINS REF=3 ATT=1 POS=1}oday t{/EXTINS}
{/VTML}
is equivalent to:
{VTML NAME="Hunting" VERS=3 author="Fabio, Ron, David"}
{ATTR ID=1 SOURCE="Hunting" VERS=3 author="Fabio" date="Aug. 17,
1996"}
{EXTINS REF=3 ATT=1 POS=1}oday t{/EXTINS}
{USROP ATT=1 NAME="SUBSTITUTION"}
{EXTDEL REF=1 POS=29 LENGTH=10}jumps over{/EXTDEL}
{EXTINS REF=2 POS=29}is not caught by{/EXTINS}
{/USROP}
{/VTML}
If VTML uses an addressing mechanism relative to the sequence of changes already performed, the POS attribute of the REF=1 EXTDEL operation points to the 29th character of the text at the current state of the document, and is thus dependent on whether the REF=3 EXTINS operation has been performed or not.
This can be avoided by specifying that all offsets for external changes are relative to a base version for that change - but this then requires that change-applying applications have indices to allow access to particular character positions in a specific version. If relative offsets are used, then external changes are not independent of their ordering, and need to be internally updated a change is undone out of sequence. If base version addressing is used, there is an additional burden on change-tracking applications as they must keep track of versions, as well as just offsets into an editing buffer.
[2] F. Vitali, D. Durand, "Using versioning to support collaboration on the WWW", Proceedings of the IV World Wide Web Conference,The World Wide Web Journal, 1(1), O'Reilly, dec. 1995. Available as: http://www.w3.org/pub/WWW/Journal/1/vitali.190/paper/190.html
[3] David G. Durand, "Palimpsest: A Data Model for Revision Control", Workshop on Collaborative Editing Systems at the CSCW '94 Conference. Available as: http://www.cs.bu.edu/students/grads/dgd/thesis/original_paper.html