|
1Language Technology Group Microsoft Research Institute Macquarie University North Ryde NSW 2113 Australia {sjgreen,rdale}@mri.mq.edu.au |
2Intelligent Interactive Technologies Group CSIRO Mathematical and Information Sciences Locked Bag 17 Sydney NSW 1670 Australia {Cecile.Paris,Maria.Milosavljevic}@cmis.csiro.au |
We have been involved in an ongoing project involving the creation of virtual documents using techniques drawn from the area of Natural Language Generation (NLG; see Reiter and Dale (1999) for an up-to-date overview of this field). In the past year, we have taken this work to a new level, by attempting to scale up the techniques we originally developed on small hand-constructed knowledge bases (KBs) to a stage where they cam be applied to a large KB that was automatically built from a database of museum objects.
This experience has illustrated some important principles to keep in mind when virtual documents on the Web meet the difficulties and inadequacies inherent in real-world data. In addition, we have gained some insight into how generation techniques can be used to produce virtual documents in multiple languages.
The forerunner of most of the systems that we have built is the Peba-II system (Milosavljevic et al., 1996), which automatically generates descriptions and comparisons of animals. These descriptions and comparisons are based on a model of the user, so that they can include references to animals that the user has already seen described.
As an experiment in seeing how domain-dependent these techniques were, we took the Peba-II system as a base and built a new database containing the kinds of objects that one would expect to see in a museum of computing. This system, Power, could be used to produce exactly the same kinds of descriptions and comparisons as Peba-II, with only a new KB and the addition of some new lexical items.
The problem with the approach taken in these two systems was that the KBs had to be constructed by hand, a time-consuming and difficult task at best. Because of this, the KBs were small, although of quite high quality. Despite this, the systems have been quite successful and have shown the feasibility of using NLG techniques in a near real-time environment like the Web (see Dale et al. (1998) for more information.)
Our success in porting Peba-II to a new domain lead us to consider how we could automatically acquire a much larger KB of objects to describe. Our interest in the museum domain is not unique - The Intelligent Labelling Explorer (Hitzman et al., 1997) project has also focussed on generating descriptions of museum gallery objects. The Powerhouse Museum was willing to provide access to the database of their Collection Information System (CIS). This database consists of approximately 300,000 objects, most of which are in storage at the museum's various facilities because of a lack of floor space in the museum's exhibition halls.
<rec num=12798 id="H4448-513">
OID: H4448-513
INT: Part
LOC: TH2.STEP.6A
LOD: 27/11/1997
OBN: Boots
OBS: Balmoral boots, elastic sided, pair, women's,
patent/kid/leather/elasticised fabric/wood,/brass prize
work, [Gundry & Sons], England, c.1851; 1862-1869.
DES: Balmoral boots, elastic sided, pair, women's,
patent/kid/leather/ elasticised fabric / wood /brass, prize
work, [Gundry & Sons], England, c.1851; 1862-1869. Pair of
women's elastic sided boots (Balmoral), with wooden filler,
of welted construction with rounded toes featuring peaked
caps and stacked heels. The uppersconsist of a patent
golosh, seamed at the back, glace kid leg, seamed at front
and back, and elastic sides extending to the golosh. The
uppers are decorated with oval stitching at the edge of
caps and scallops at the throat of golosh. The leather
heel is fine wheeled, featuring a top piece with brass
nailed edge. The black leather sole features a sueded
forepart with brass nails, as well as an internal clump and
brass hinged section for extra strength and a brown
polished ridged waist with black edge. Reputed to have
been made by Gundry & Sons. (See object file for
specialist report by June Swann)
MDE: Gundry & Sons; London, England
MDN: 1965 list says "made by Gundry & Sons, Soho Square." Swann
says hinged device to increase flexibility is
unusual. Similar screws on H4448-515. Note hinged sole in
1862 exhibition. She finds no information about Box in
information she has about the 1851 exhibition, though
William Walsh is mentioned in connection with a pair of
shoes. Patent 558, 5 March 1861, granted to J.M. Carter, a
similar sole with 2 cuts across the tread and 4 rows of
screws "for soldiers, riflemen, sportsmen. The inner sole
is whole and contains pitch." It is not possible to
confirm whether these boots contain pitch.
DAT: c 1851 - 1869
MAR: Interior obscured by last, no marks on exterior
DIM: Length 248 mm Height 31 mm Overall Height 160 mm Width 58 mm
</rec>
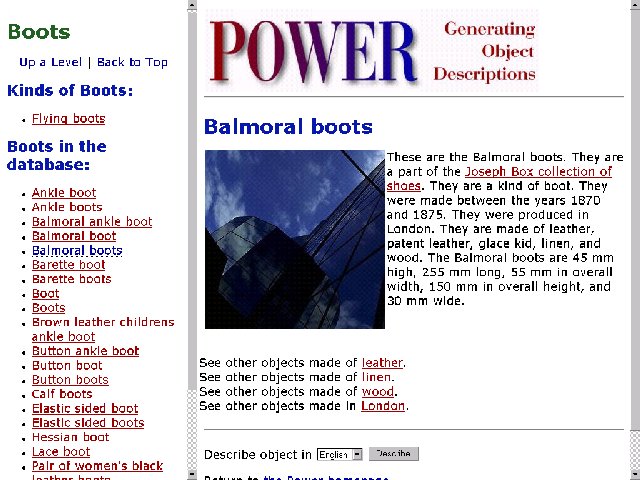
We selected as a subset of the items in the database only those objects on display in the museum. We also included in this set all those objects in the database that were a part of something on display, even if these particular objects were not on display. This subset amounted to approximately 15,000 objects. Figures 1 and 2 demonstrate the range of data quality in the database. The entry in Figure 1 provides a rather complete description of the Balmoral boots, including a discussion on the construction and history of the boots. The entry in figure 2, on the other hand, provides no information beyond that required for a database record to actually exist! It is worth noting that this database was intended for internal use by curators only, and not intended to be used to generate object descriptions for public consumption.
<rec num=15463 id="PROP/EXP/82">
OID: PROP/EXP/82
INT: PROP
LOC: EH2.EXP.3H
LOD: 16/02/1996
OBS: Aerosol deodorants/colognes (2), "Lynx" & "Australis".
DES: Aerosol deodorants/colognes (2), "Lynx" & "Australis".
</rec>
In addition to the database, we were provided with a hierarchical thesaurus of objects that had been prepared by the museum. With these two information sources, and with lists of countries and materials extracted from the Macquarie Thesaurus we could begin the process of extracting a KB from the database. The extraction process is broken down into five basic steps:
Clearly the quality of the KB entries created will depend greatly on the database they are extracted from. For example, of the 15,483 records that we received in the database dump, only 9,887 (in other words, around 64% of the total) actually have an OBN field. Furthermore, of the 9,887 objects that have OBN fields, only 7,751 are valid object names, that is to say that the Object Name assigned to the object appears in the museum thesaurus. Thus, about 50% of the database entries do not provide any information about the types of the objects.
Even a high-quality entry, such as that in Figure 1, is problematic, as much of the information that we would like to put in a description is "locked-up" in text. In Figure 1, we see this in the description of the construction of the boot. Although much recent work in Natural Language Processing is oriented towards extracting useful information from texts that have some similar characteristics, current techniques are simply not up to the task of performing this extracting reliably in such a way that results are reusable for our purposes. We cannot simply use the text directly, as we cannot guarantee that the text will be well structured or even relevant. In addition, the text may contain information that the public viewing these descriptions are not meant to know. A more-structured database would make this task significantly easier. Figure 3 shows the generated text for the database entry in Figure 1.
In the Peba-II and Power systems, the task of navigating the virtual document space was accomplished by selecting items of interest from a list and then following hypertext links around the object hierarchy. This is sufficient when there is only a small number of objects and a user can easily look through a list of them. When we move to a KB consisting of thousands of objects, however, we need to rethink our navigation strategy. It is, to say the least, infeasible (and perhaps impossible in current browsers) to have a user select an item of interest from a list of 15,000.
The obvious choice for a navigation strategy is to use the object hierarchy provided by the Powerhouse. This has the advantage that we can use a structure that was built by humans and which therefore should represent the actual relationships between the objects in the database. Given the thesaurus and the generated KB, we can produce a hierarchy that will allow a user to navigate from the top level to a specific object. Currently, this navigation hierarchy is a static set of pages that is generated when the KB is regenerated, but there is no reason why it cannot be dynamic too.
As the location of the objects in the museum is also encoded in the database entries, we built a navigation hierarchy based on location. The location information includes the exhibit that an object is part of as well as the case in which it appears. We found, however, that such a hierarchy offered little help to users, since they had no idea what was in the exhibits, let alone which objects were gathered in something called "Case 6A".
While using the thesaurus-based navigation hierarchy allows a user to navigate to an object by traversing through classes and subclasses, it will not allow them to navigate directly from one object to another. Our aim in building the generation component was to make sure that any systematic relationships between objects (e.g., that one is a part of another, or they were manufactured by the same artisan) is expressed in the virtual document as a hypertext link. This is implemented simply as a set of inverted files to which the generation component has access.
Our initial approach was to inline all of these links into the text, but this led to some confusion about the discourse intention of following the links (see Milosavljevic and Oberlander (1998) for a discussion of dynamic hypertext as discourse). In the original Peba and Power systems, only the names of objects were linked. The discourse intention of following one of these links was clear: "describe this animal" or "describe this computer". However, when more than one kind of entity is linked, the intention is less clear. For example, if the user follows a link whose anchor is the word leather, will he or she be taken to a description of the material leather or to a listing of the objects in the database that are made of leather?
Our solution was simply to make the discourse intentions for links other than links to named entities very explicit, leading to constructions such as See other objects made of leather appearing at the end of the descriptions of objects.
Although we are claiming to be porting the Peba-II/Power system to an automatically generated KB, in fact, we have completely re-written the system to take advantage of some of the lessons learned during the development of the previous systems. As with any re-write, there have been some changes in functionality.
Unlike the ancestor systems, the current system will not generate comparisons. There is no fundamental reason why this cannot be done, but there is no obvious way to introduce a comparison to the user. In the original systems, comparisons were generated either by selecting two objects from two lists of all the objects known to the system or by selecting another object when looking at a description of some object. Needless to say, this is ineffective when there are 15,000 objects to choose from.
Another factor limiting the scope for providing comparisons is that, in the hand-crafted KB used previously, the KB author was able to specify objects that could be confused with the given object, along with other useful properties that might play a role in comparison. These potential confusors are not available in the automatically generated KB. We are still exploring the appropriate use of comparisons in this context, but see Milosavljevic and Oberlander (1998) for more information.
A major change for the better is that the current system is fully multilingual, with descriptions available in English, French, Spanish, Dutch, and Chinese. The main difficulty with the multilinguality is that one of the major components of the database is the names of the objects themselves. Translating these names to each of the target languages is a daunting (but not impossible) task. Currently, the English names of items are always shown. Figure 4 shows the text of the description shown in Figure 3 in French and Spanish.
Ces objects sont des `Balmoral boots'. Ils ont ete fabriques en entre 1870 et 1875. Ils ont ete fabriques a `London'. Ils sont en `leather', patent leather, glace kid, `linen' et `wood'. Les `Balmoral boots' sont 45 mm de hauteur, 255 mm de longeur, 55 mm de largeur total, 150 mm de hauteur total et 30 mm de largeur.
Estos son `Balmoral boots'. Fueron hechos entre los ańos 1870 y 1875. Fue producido en `London', Inglaterra. Están hechos de cuero, patent leather, glace kid, lino y madera. Los `Balmoral boots' tienen 45 mm de altura, 255 mm de largo, 55 mm de anchura total, 150 mm de altura total y 30 mm de ancho.
For some of the smaller sets of lexical items (e.g., materials and places), translations have and are continuing to be made. These are presented to the user in the target language. Adding a new language is straightforward, requiring the translation of about 400 materials and countries and the translation of the template sentences used by the generator.
Clearly, we could improve the quality of the texts generated if we could do a better job of extracting information from the database of objects. Unfortunately, this is currently out of our hands. The experience would have been very different if the database had been more consistently marked-up with XML or another representation language.
The lack of typed links on the Web leads us to produce texts that are probably less fluent than they could be. If it were possible to specify exactly what discourse intention would be understood by the user following a particular link, then we could do away with the lists of links at the bottom of each text that we produce. This would appear to be possible under the current extended linking proposal for XLink.
One of the advantages of a hand-crafted KB is that it is a relatively straightforward task to specify possible links between objects while building it. Although we could use a similarity metric to propose links between items based on the KB features that they have in common, the sparseness of our current data would mean that most such comparisons would be based on size. It may be that we can resort to using IR-like techniques (see Green, 1997) to automatically determine which objects are related, but this will most likely only work for the textually rich objects. By the same token, this would allow us to make use of data that we are currently ignoring.
Finally, there is no straightforward (or perhaps integrated) way to get an overview of what the information space underlying the system is. There is currently no way for a user to get some idea of how many things there are to look at or how to get to them.
(Bernard, 1990) Bernard J. Ed. The Macquarie Thesaurus. Macquarie Library, North Ryde NSW. 1990.
(Dale et al., 1998) Robert Dale, Jon Oberlander, Maria Milosavljevic and Alistair Knott. Integrating natural language generation and hypertext to produce dynamic documents. Interacting with Computers. 11(2). 15 December 1998.
(Green, 1997) Stephen J. Green. Automated link generation: Can we do better than term repetition?. In Proceedings of the Seventh International World Wide Web Conference, April, 1998, Brisbane, Australia, pp. 75--84.
(Hitzman et al., 1997) Hitzeman J., Mellish C. and Oberlander J. Dynamic generation of museum web pages: The intelligent labelling explorer. Archives and Museum Informatics, 11:105--112. 1997.
(Milosavljevic et al., 1996) Maria Milosavljevic, Adrian Tulloch and Robert Dale. 1996. Text Generation in a Dynamic Hypertext Environment. In Proceedings of the Nineteenth Australasian Computer Science Conference (ACSC'96), Melbourne, Australia. 31 January - 2 February 1996, 417-426.
(Milosavljevic and Oberlander, 1998) Maria Milosavljevic and Jon Oberlander. 1998. Dynamic Hypertext Catalogues: Helping Users to Help Themselves. In the Proceedings of the 9th ACM Conference on Hypertext and Hypermedia, Pittsburgh, PA, USA, 20-24 June 1998.
(Reiter and Dale, 1999) Ehud Reiter and Robert Dale. 1999. Building Natural Language Generation Systems. Cambridge University Press.